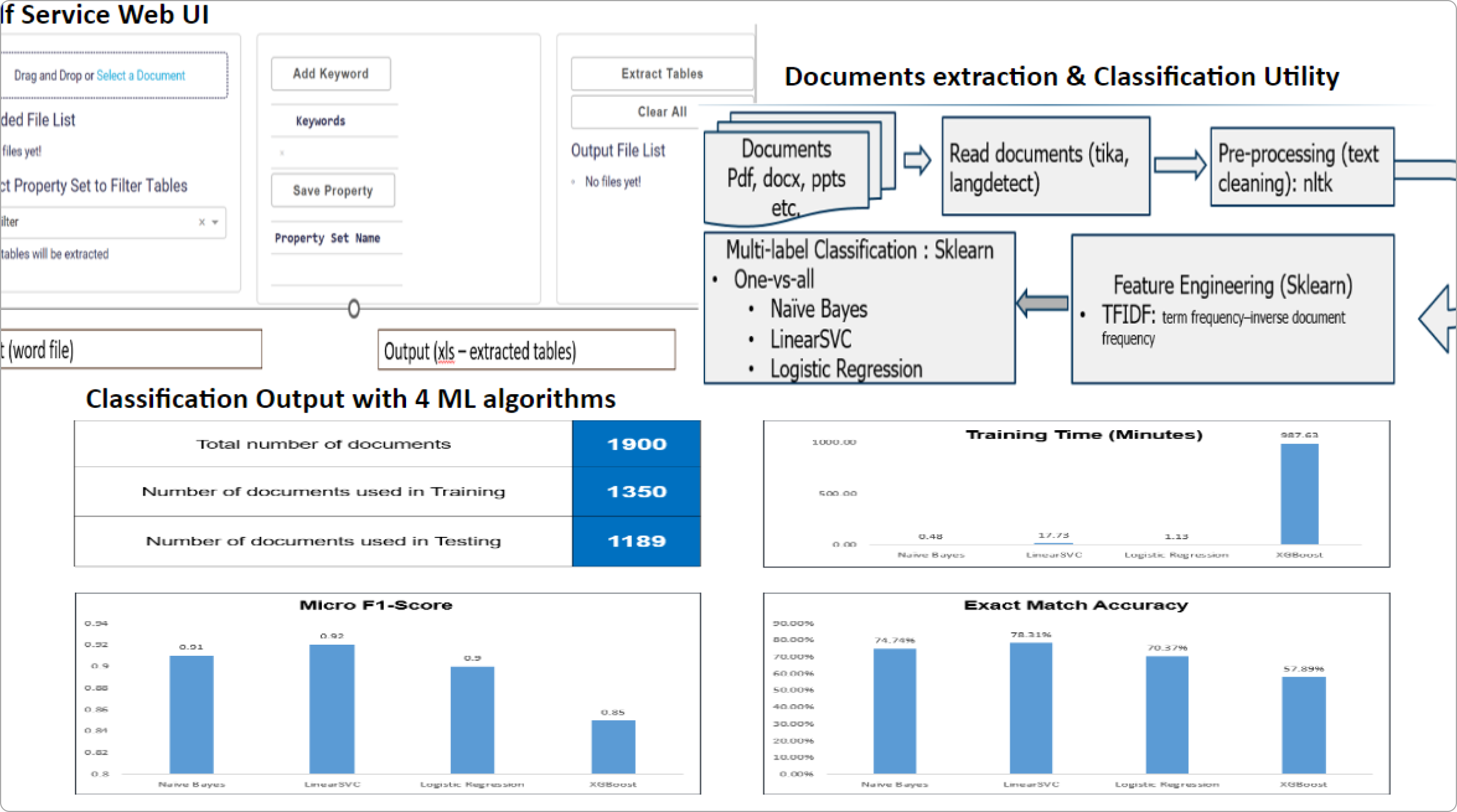
Packaged Framework – Process and Technology for Text extraction and structured search
Pre-build custom solutions with Python libraries and AWS – textract
Packaged Framework – Process and Technology for Text extraction and structured search
Pre-build custom solutions with Python libraries and AWS – textract